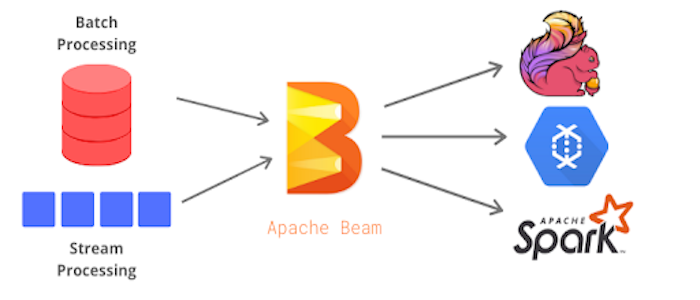

Apache Beam is an open source, unified model for defining both batch and streaming data-parallel processing pipelines. Using one of the open source Beam SDKs, you build a program that defines the pipeline. The pipeline is then executed by one of Beam’s supported distributed processing back-ends, which include Apache Apex, Apache Flink, Apache Spark, and Google Cloud Dataflow.
This is session 2 of the series:
Data Engineering is a very interesting field, with lots of new technologies, and opportunities. Unfortunately, it takes a long time to master, and there arenot many resources for intermediate practitioners
In this talk, we will take a public dataset and a concept, and we will build an Apache Beam pipeline that is stable and ready to run in production. We will walk through the workflow of starting the project in an IDE, writing and organizing pipeline code, as well as writing tests, and running them. You can adapt this model for your own pipeline, and I will be happy to answer your questions!
For more talks on Apache Beam, join and watch our Session 1 on May 6th, 10am PST. Link